S3 Không Phải Là Database: Cách Thiết Kế Kiến Trúc Như Một Database
Phân tích kỹ thuật chuyên sâu về bố cục object, kích thước file, compaction và read amplification
TL;DR
S3 và các object store tương tự thiếu các tính năng cơ bản của database—index, transaction và khả năng lookup hiệu quả. Tuy nhiên, các nền tảng dữ liệu hiện đại thường xuyên sử dụng chúng như analytical database. Bài viết này giải thích cách thu hẹp khoảng cách đó thông qua các lựa chọn kiến trúc có chủ đích: phân vùng dự đoán được để tránh các thao tác listing tốn kém, điều chỉnh kích thước file để cân bằng giữa tính song song và overhead của metadata, compaction lấy cảm hứng từ LSM để kiểm soát write và read amplification, và sử dụng chiến lược các định dạng columnar với thống kê để giảm thiểu việc quét không cần thiết. Chúng ta sẽ xem xét các triển khai thực tế từ Delta Lake, Iceberg và Hudi để thấy các pattern này trong thực tế.
Tại Sao Điều Này Quan Trọng
Object storage cung cấp khả năng mở rộng hầu như không giới hạn và tách biệt compute khỏi storage—những lợi thế quan trọng cho các nền tảng dữ liệu hiện đại. Nhưng API của nó về cơ bản khác với database:
- Không có index: Mọi query đều có khả năng phải quét toàn bộ
- Không có transaction: Các writer đồng thời có thể làm hỏng state
- LIST operation rất tốn kém: Việc phát hiện file nào tồn tại không scale được
- Độ trễ cao: Việc fetch một object riêng lẻ mất vài millisecond, không phải microsecond
- Object bất biến: Update yêu cầu ghi lại toàn bộ file
Các team bỏ qua những ràng buộc này sẽ có hệ thống bị nghẽn dưới áp lực metadata, gặp "hội chứng file nhỏ" (small file syndrome), hoặc phải quét hàng terabyte để trả lời các query đơn giản. Tin tốt: một thập kỷ phát triển lakehouse đã tạo ra các pattern đã được thử nghiệm. Hãy cùng khám phá chúng.
1. Object Layout: Làm S3 Có Thể Dự Đoán Được
Vấn đề cơ bản với object store là chi phí listing. Khi bạn có hàng tỷ object, các thao tác LIST trở nên cực kỳ tốn kém. Giải pháp là tổ chức dữ liệu sao cho các engine có thể dự đoán object nào quan trọng mà không cần list tất cả.
Các Scheme Phân Vùng
Hive-style partitioning vẫn là pattern chủ lực. Bằng cách mã hóa giá trị partition trong key prefix (s3://bucket/table/year=2024/month=01/day=15/), bạn cho phép query planner loại bỏ toàn bộ cây thư mục trước khi thực hiện bất kỳ lệnh gọi LIST nào 1. Điều này hoạt động tuyệt vời khi các predicate của query phù hợp với các cột partition.
# Tốt: Phù hợp với các pattern query phổ biến
s3://data-lake/events/
year=2024/
month=01/
day=15/
part-00000.parquet
part-00001.parquet
Date-based partitioning là một dạng chuyên biệt được tối ưu hóa cho workload time-series. Hầu hết các analytical query đều lọc theo cửa sổ thời gian, khiến phân vùng theo thời gian trở nên phù hợp tự nhiên. Các table format tối ưu hóa rõ ràng cho việc pruning partition theo ngày 12.
Hash-based partitioning (bucketing) giải quyết một vấn đề khác: write hotspot và kích thước partition không giới hạn. Bằng cách phân phối dữ liệu qua các bucket cố định sử dụng hàm hash, bạn giới hạn số lượng file trên mỗi logical partition và phân tán tải I/O qua các prefix 3:
# Hash bucketing trong date partition
s3://data-lake/events/
year=2024/month=01/day=15/
bucket_00/
bucket_01/
...
bucket_31/
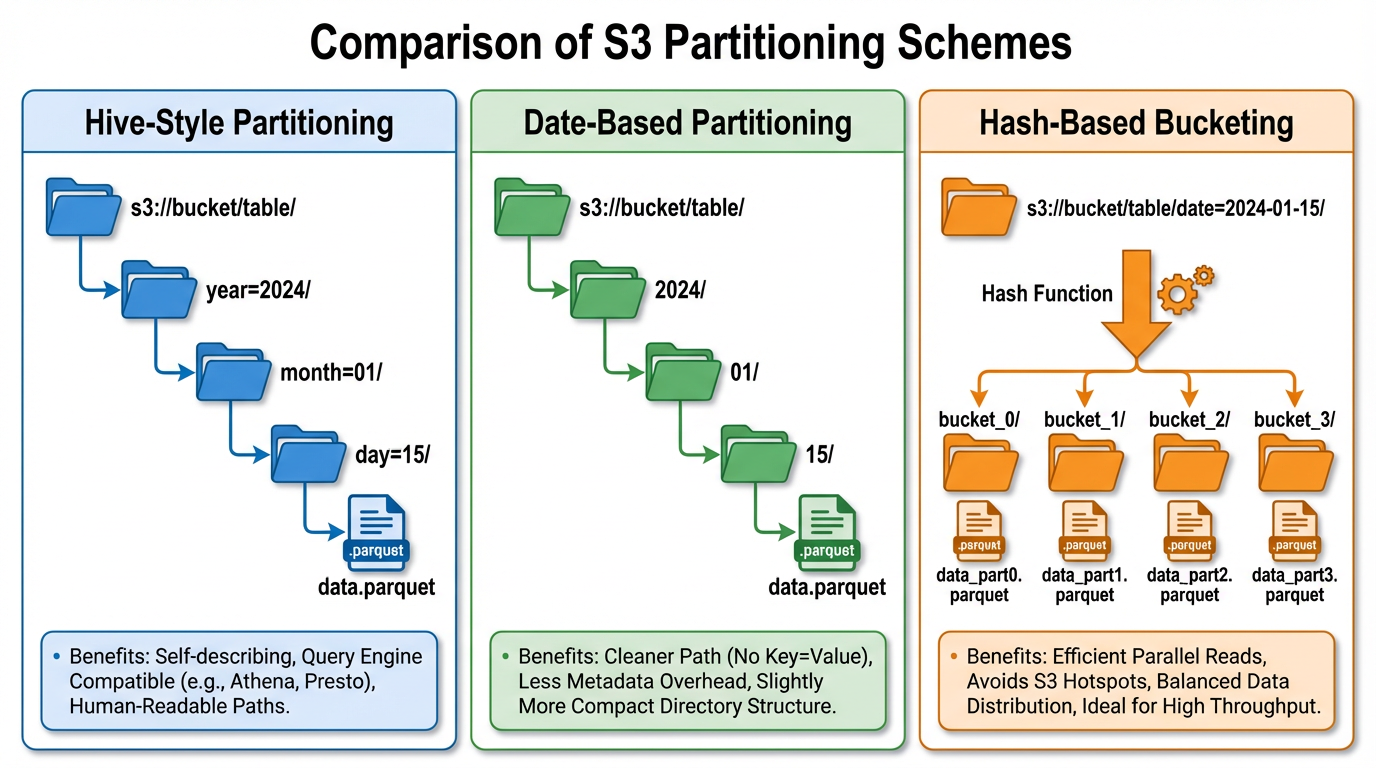
Thiết Kế Prefix và Tránh Hotspot
Kiến trúc nội bộ của S3 có thể tạo hotspot khi quá nhiều request nhắm vào cùng một prefix. Mặc dù AWS đã phần lớn giảm thiểu điều này bằng automatic partitioning, nguyên tắc vẫn là: phân tán write load qua các prefix.
Vấn đề lớn hơn là chi phí listing. Với hàng tỷ object, ngay cả các thao tác LIST phân trang cũng trở thành bottleneck. Giải pháp là tránh listing hoàn toàn bằng cách duy trì metadata riêng biệt—điều này đưa chúng ta đến tổ chức metadata.
Tổ Chức Metadata
Đây là nơi các table format thể hiện giá trị. Thay vì listing S3 để phát hiện data file, hãy duy trì một transaction log compact hoặc cấu trúc manifest:
Delta Lake sử dụng transaction log append-only được compact định kỳ thành các Parquet checkpoint. Khi bạn query một bảng, bạn đọc log (thường là một vài file JSON nhỏ) thay vì listing bucket. Điều này tăng tốc các thao tác metadata theo bậc độ lớn 1.
s3://bucket/table/
_delta_log/
00000000000000000000.json
00000000000000000001.json
...
00000000000000000020.checkpoint.parquet # Metadata đã compact
Apache Iceberg sử dụng mô hình manifest-of-manifests. File metadata cấp cao nhất trỏ đến manifest list, từ đó trỏ đến manifest, cuối cùng mô tả các data file. Hệ thống phân cấp này cho phép planner prune ở nhiều cấp độ mà không cần chạm vào data object 4:
metadata/
v1.metadata.json # Snapshot cấp cao nhất
snap-123.avro # Manifest list
manifest-abc.avro # Metadata per-file
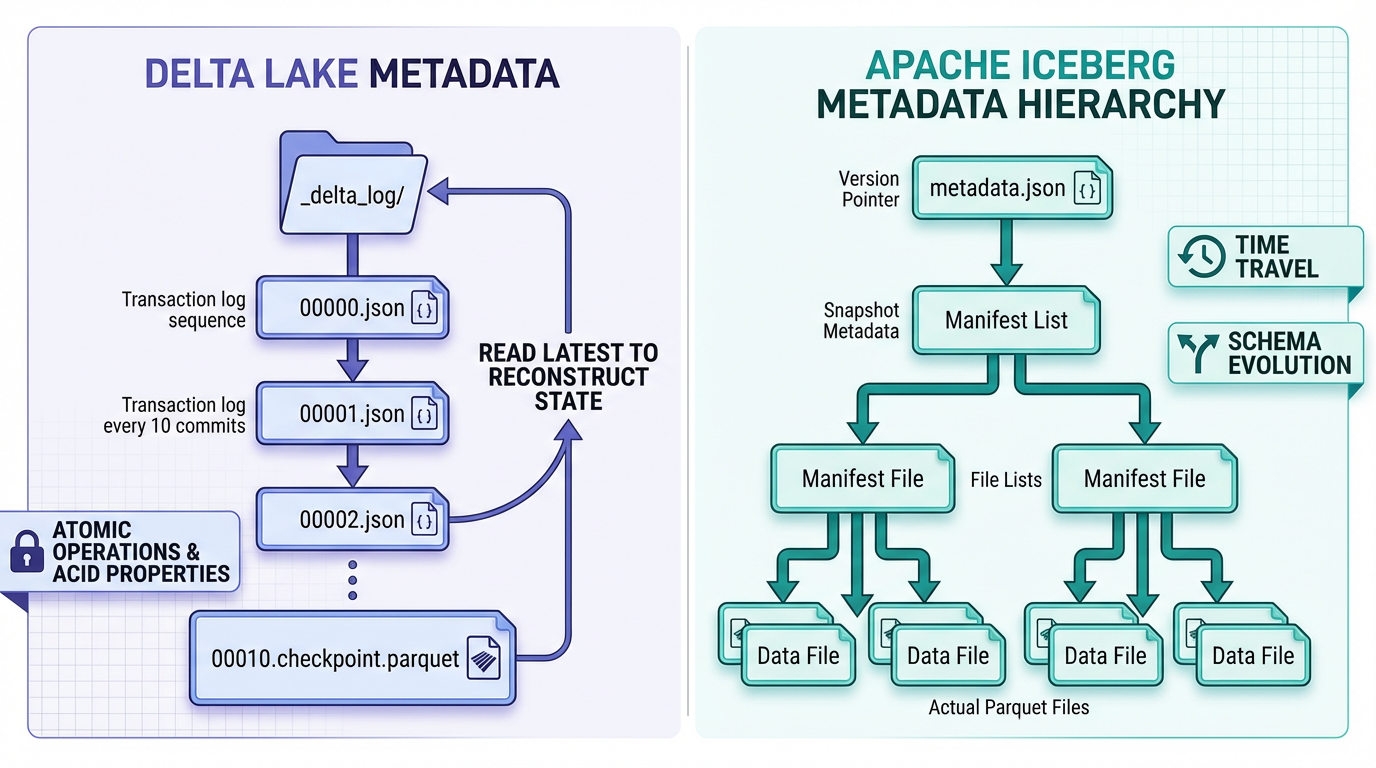
Insight chính: coi metadata như một concern hạng nhất. Listing S3 không scale được; các cấu trúc metadata compact thì có thể.
Best Practice Về Cấu Trúc Thư Mục
- Căn chỉnh physical layout với query predicate: Nếu người dùng luôn lọc theo
customer_id, hãy partition theo nó - Tránh hệ thống phân cấp sâu: Hơn 3-4 cấp partition tạo ra độ phức tạp mà không có lợi ích
- Đặt các update liên quan gần nhau: Giữ các file delta nhỏ gần dữ liệu chúng sửa đổi để đơn giản hóa compaction 5
2. Kích Thước File: Vấn Đề Goldilocks
Kích thước file là một khía cạnh quan trọng nhưng thường bị hiểu sai. Quá nhỏ tạo ra metadata explosion; quá lớn gây read amplification và giảm tính song song.
Vấn Đề File Nhỏ
Nhiều file nhỏ là nỗi ác mộng của object-store analytics:
- Metadata overhead: Mỗi file yêu cầu một LIST entry, một metadata fetch và đọc footer
- Planning overhead: Query planner phải xử lý hàng nghìn hoặc hàng triệu file-level statistic
- Opening overhead: Thiết lập kết nối và đọc header cho mỗi file nhỏ tích lũy lại
- Giảm throughput: Engine dành nhiều thời gian cho coordination hơn là xử lý dữ liệu
Các table format được phát minh phần lớn để giải quyết điều này. Bằng cách theo dõi file trong metadata compact thay vì dựa vào LIST, chúng giảm chi phí planning. Nhưng chúng không loại bỏ hoàn toàn vấn đề—reader vẫn phải mở mọi file 13.
Vấn Đề File Lớn
Ở cực đối diện, các file nguyên khối multi-gigabyte gây ra các vấn đề khác:
- Read amplification: Chọn 10 hàng từ file 5GB vẫn yêu cầu fetch lượng dữ liệu đáng kể
- Giảm tính song song: Ít file hơn có nghĩa là ít task hơn, không tận dụng hết tài nguyên cluster
- Column pruning kém: Ngay cả với định dạng columnar, các file rất lớn có row group thô
Giải pháp không phải là một con số ma thuật duy nhất—mà là điều chỉnh cấu trúc bên trong.
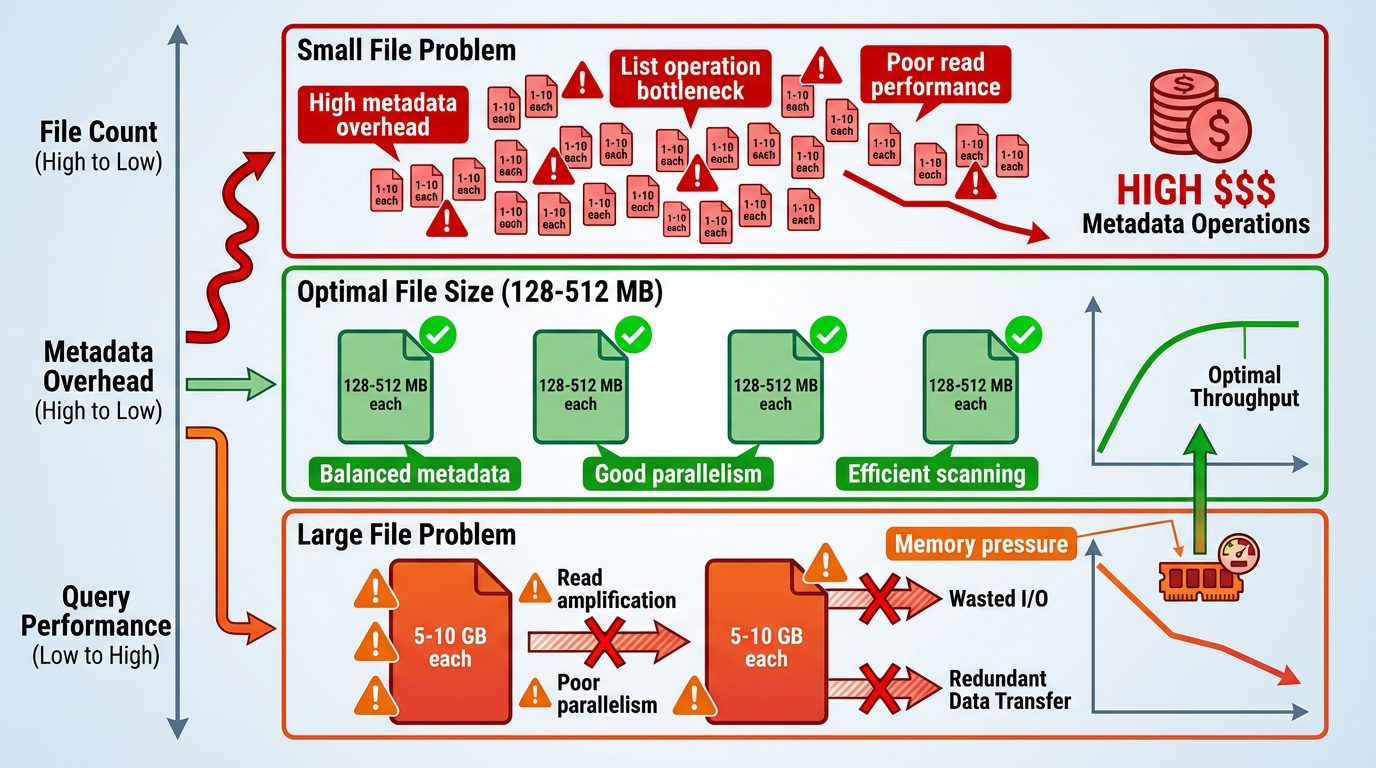
Sweet Spot (Tùy Thuộc Vào Workload)
Nghiên cứu về cloud-optimized columnar storage nhấn mạnh việc tối ưu hóa cấu trúc within-file (row group, stripe) hơn là chỉ kích thước file 67. Tuy nhiên, hướng dẫn thực tế:
Cho OLAP scan workload:
- Mục tiêu 128MB đến 1GB mỗi file cho Parquet/ORC
- Cấu hình row group ở 128MB đến 256MB cho column pruning tốt
- Hướng tới hàng trăm đến vài nghìn file mỗi partition, không phải hàng triệu
Cho streaming/incremental ingestion:
- Chấp nhận file nhỏ hơn (10MB-100MB) từ việc ghi thường xuyên
- Compact mạnh mẽ để ngăn tích tụ
- Sử dụng adaptive buffering để batch các micro-batch 5
Cho mixed workload:
- Tách hot data (gần đây, cập nhật thường xuyên) khỏi cold data (lịch sử, read-only)
- Tối ưu hóa cold data mạnh mẽ (file lớn hơn, nén tốt hơn)
- Giữ hot data trong file nhỏ hơn để compaction nhanh hơn
Trigger Compaction
Khi nào nên compact? Các heuristic phổ biến:
- Ngưỡng số lượng file: >1000 file nhỏ trong một partition
- Phân phối kích thước: >50% file dưới 64MB
- Read amplification: Query quét >10 file mỗi task
- Dựa trên thời gian: Compaction được lên lịch hàng ngày/tuần cho cold partition
Chìa khóa là đo lường. Instrument hệ thống của bạn để theo dõi:
- Số file trung bình mỗi query
- Độ trễ metadata operation
- Tỷ lệ read amplification (byte quét / byte trả về)
3. Chiến Lược Compaction: Học Từ LSM-Tree
Compaction là quá trình ghi lại các file nhỏ hoặc phân mảnh thành layout tối ưu. Nó được vay mượn từ các LSM-tree database như RocksDB, được điều chỉnh cho immutable object storage.
Minor vs Major Compaction
Minor compaction là thường xuyên và cục bộ:
- Merge 10-100 file nhỏ gần đây thành một vài file lớn hơn
- Chạy liên tục trong background
- Chi phí tài nguyên thấp, lợi ích ngay lập tức cho read performance
- Giảm áp lực metadata mà không cần ghi lại toàn bộ partition 5
Major compaction là không thường xuyên và toàn cục:
- Ghi lại toàn bộ partition để có layout tối ưu
- Áp dụng các tối ưu hóa nâng cao (Z-ordering, clustering)
- Tốn nhiều tài nguyên, thường được lên lịch trong giờ thấp điểm
- Cung cấp hiệu suất đọc tối đa và metadata compaction 15
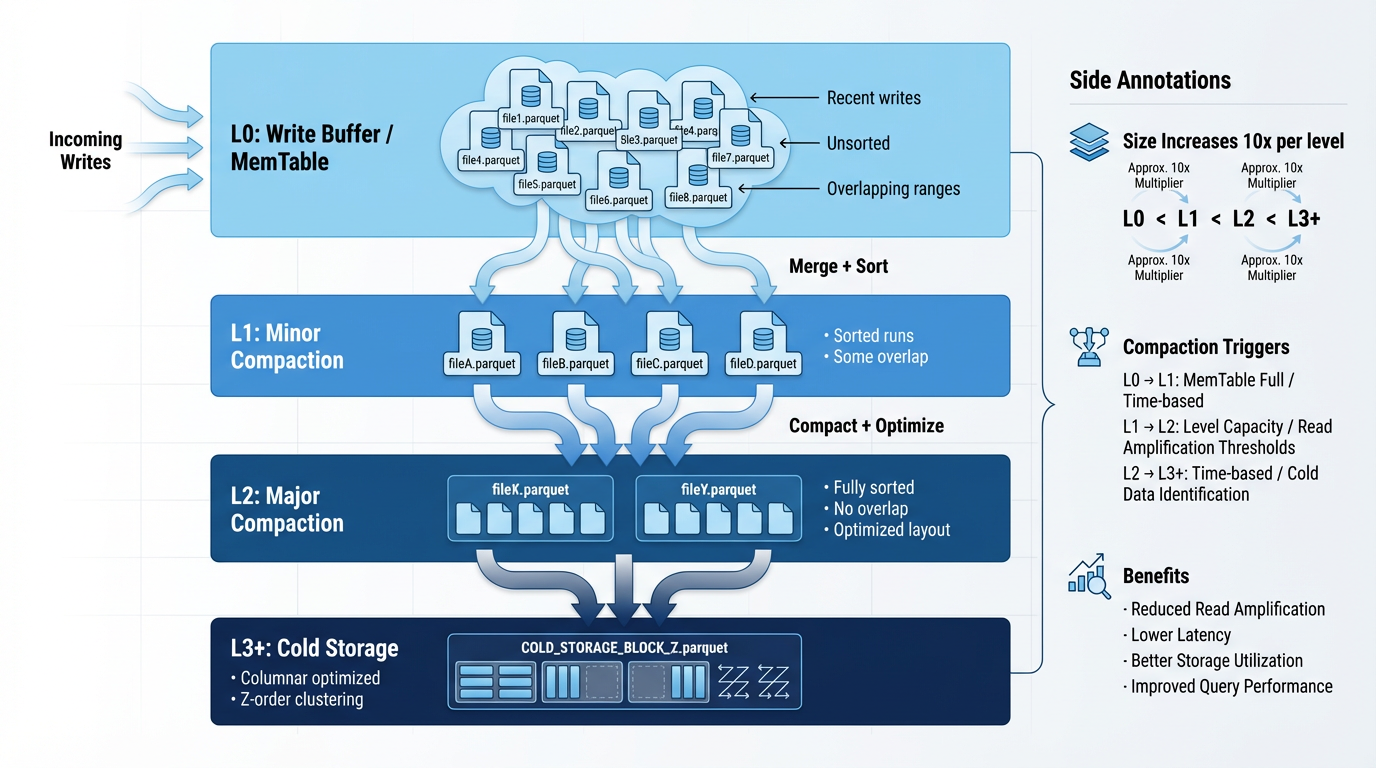
Kỹ Thuật Lấy Cảm Hứng Từ LSM-Tree
Mô hình LSM-tree ánh xạ tuyệt vời với object storage:
- Ghi dữ liệu mới dưới dạng file nhỏ bất biến (L0 tier)
- Định kỳ merge các file L0 vào L1 (minor compaction)
- Merge các file L1 vào L2 khi đạt ngưỡng (major compaction)
- Giữ kích thước tier bị giới hạn để kiểm soát write amplification
Cách tiếp cận phân tầng này giới hạn số lượng file mà reader phải quét trong khi giữ công việc compaction ở mức tăng dần 83.
Delta Lake compact chính transaction log của nó—khi log phát triển quá lớn, nó được compact thành Parquet checkpoint. Metadata compaction này quan trọng không kém data compaction 1.
Apache Iceberg hỗ trợ các thao tác file rewrite rõ ràng và manifest-level pruning. Nó có thể compact manifest riêng biệt với data file, tối ưu hóa metadata độc lập 4.
Lên Lịch Compaction và Quản Lý Tài Nguyên
Compaction tốn nhiều I/O và CPU. Best practice:
- Chạy minor compaction liên tục với priority thấp
- Lên lịch major compaction trong maintenance window hoặc thời gian ít traffic
- Throttle compaction I/O để tránh ảnh hưởng đến query workload
- Sử dụng cluster compute riêng cho compaction nếu có thể
- Làm cho compaction policy có thể cấu hình theo table/partition
Các hệ thống production coi compaction như một mối quan tâm về capacity planning, không phải là điều suy nghĩ sau 53.
Write Amplification vs Read Performance
Compaction tạo ra một trade-off cơ bản:
- Aggressive compaction → Read amplification thấp, write amplification cao
- Lazy compaction → Read amplification cao, write amplification thấp
Sự cân bằng thực tế được sử dụng bởi các lakehouse system:
- Incremental compaction cho dữ liệu gần đây (write amplification thấp)
- Occasional major rewrite cho tối ưu hóa dài hạn
- Partition-level policy compact các hot partition mạnh mẽ hơn 15
4. Giảm Thiểu Read Amplification
Read amplification—quét nhiều dữ liệu hơn cần thiết—là kẻ thù của query performance. Đây là cách chống lại nó.
Column Pruning và Predicate Pushdown
Đây là điều cơ bản cho các định dạng columnar. Engine phải:
- Push column projection vào file reader để chỉ các cột cần thiết được deserialize
- Push filter predicate xuống để bỏ qua các row group không khớp
- Sử dụng file footer metadata để tránh mở các file không thể chứa kết quả 69
Parquet và ORC được thiết kế cho điều này, nhưng bạn phải điều chỉnh kích thước row group để có được lợi ích. Row group quá lớn giảm độ chi tiết pruning; quá nhỏ tăng footer overhead.
Zone Map, Bloom Filter và Statistic
File-level statistic cho phép pruning mà không cần đọc dữ liệu:
{
"file": "part-00000.parquet",
"row_count": 1000000,
"column_stats": {
"user_id": { "min": 1, "max": 50000 },
"timestamp": { "min": "2024-01-01", "max": "2024-01-31" }
}
}
Nếu một query lọc user_id > 60000, planner bỏ qua file này hoàn toàn.
Bloom filter mở rộng điều này cho equality predicate. Iceberg và Hudi hỗ trợ per-file bloom filter cho các cột high-cardinality, cho phép kiểm tra membership nhanh 410.
Zone map (min/max index) được duy trì ở cả:
- File level (trong table metadata)
- Row group level (trong Parquet footer)
Cách tiếp cận hai tầng này cho phép pruning thô trong quá trình planning và pruning tinh trong quá trình scanning 7.
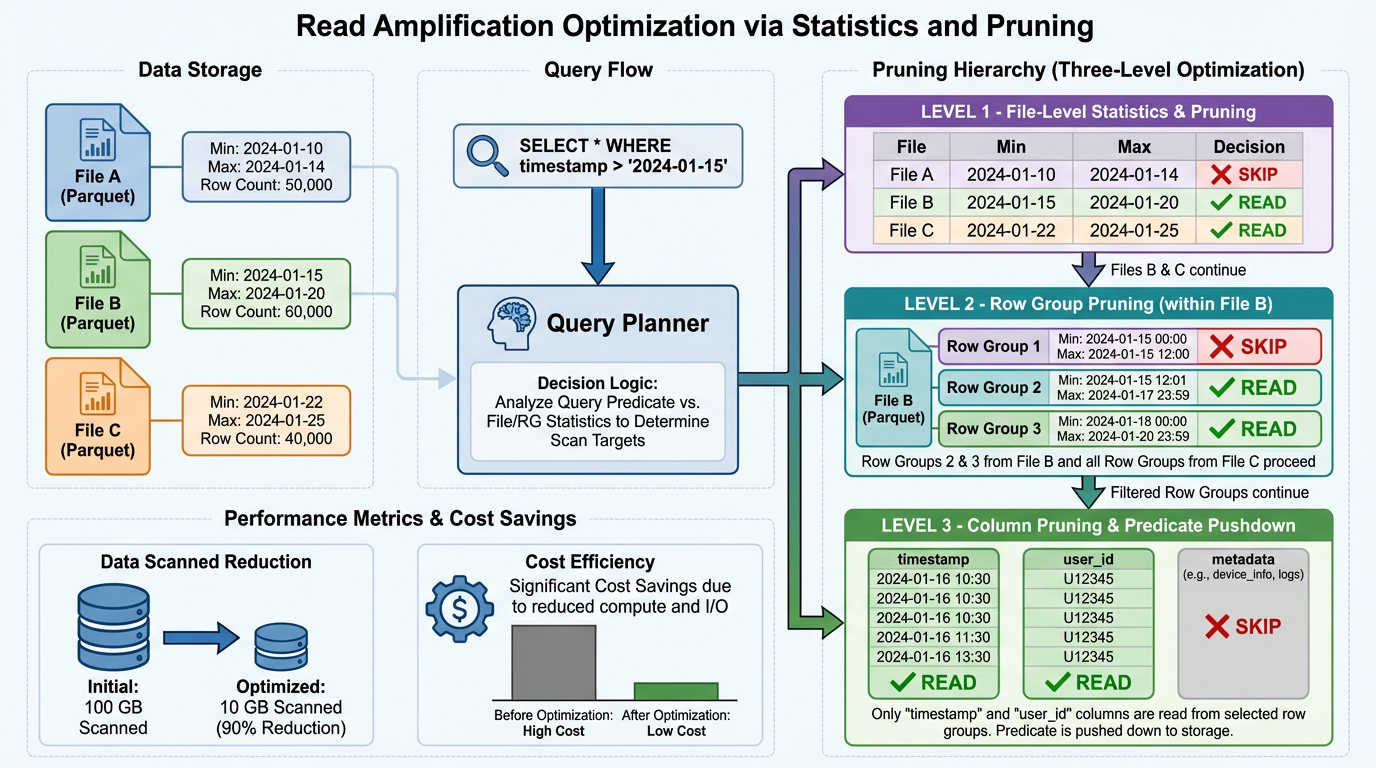
Tối Ưu Hóa Parquet/ORC Row Group
Đây là nơi phép màu xảy ra. Điều chỉnh kích thước row group cân bằng:
- Row group lớn hơn → Footer overhead ít hơn, nén tốt hơn
- Row group nhỏ hơn → Pruning chi tiết hơn, selectivity tốt hơn
Nghiên cứu cho thấy rằng tối ưu hóa layout trong và qua các ranh giới row group cung cấp lợi ích throughput đáng kể trên cloud object storage 6. Khuyến nghị thực tế:
- 128MB row group cho general-purpose analytics
- 256MB row group cho scan-heavy workload
- 64MB row group cho highly selective query
Cũng xem xét row group alignment:
- Sắp xếp dữ liệu trước khi ghi để cluster các giá trị liên quan
- Sử dụng Z-ordering hoặc Hilbert curve cho multi-dimensional clustering
- Lệnh OPTIMIZE của Delta Lake triển khai điều này 1
Metadata-First Planning
Insight chính: làm cho planning rẻ bằng cách giữ metadata compact và tách biệt khỏi dữ liệu.
Các table format hiện đại lưu trữ:
- Per-file statistic (row count, column min/max, null count)
- Per-row-group statistic (cho pruning tinh hơn)
- Partition information
- Schema evolution history
Metadata này được lưu trữ trong các file Avro hoặc Parquet compact, không phải trong chính data file. Planner đọc metadata trước, prune mạnh mẽ, sau đó chỉ đọc tập hợp tối thiểu các data file 41.
5. Triển Khai Thực Tế
Hãy xem các table format chính áp dụng các nguyên tắc này như thế nào.
Delta Lake
Cách tiếp cận: Transaction log với compaction định kỳ
Xử lý file nhỏ:
- Transaction log theo dõi tất cả file mà không cần S3 listing
- Log compaction hợp nhất các entry thành Parquet checkpoint
- Lệnh OPTIMIZE trigger data file compaction 1
Thuật toán compaction:
- Manual qua OPTIMIZE hoặc scheduled job
- Hỗ trợ Z-ordering cho multi-dimensional clustering
- Có thể compact cả data file và transaction log
Quản lý metadata:
- Append-only JSON log cho atomicity
- Periodic Parquet checkpoint cho fast read
- Time travel qua log replay 1
Tốt nhất cho: Team muốn operation đơn giản với ACID guarantee
Apache Iceberg
Cách tiếp cận: Manifest-of-manifests với snapshot isolation
Xử lý file nhỏ:
- Manifest theo dõi file, tránh các thao tác LIST lặp lại
- Manifest compaction tách biệt với data compaction
- File-level statistic cho phép aggressive pruning 4
Thuật toán compaction:
- Explicit rewrite operation qua API
- Hỗ trợ cả copy-on-write và merge-on-read
- Deletion vector cho delete hiệu quả 10
Quản lý metadata:
- Immutable metadata file với snapshot pointer
- Manifest list cho hierarchical pruning
- Extensive per-file statistic (min/max, null count, bloom filter) 4
Tốt nhất cho: Team cần kiểm soát chi tiết và multi-engine compatibility
Apache Hudi
Cách tiếp cận: Dual-mode với Copy-on-Write và Merge-on-Read
Xử lý file nhỏ:
- COW: Ghi lại file ngay lập tức, tránh tích tụ file nhỏ
- MOR: Chấp nhận delta log nhỏ, compact bất đồng bộ 311
Thuật toán compaction:
- MOR: Incremental log được merge vào base file định kỳ
- COW: Không cần compaction, file đã được tối ưu hóa
- Configurable compaction strategy theo table 3
Quản lý metadata:
- Timeline service theo dõi commit và compaction
- File-level index cho upsert và incremental read
- Metadata table cho fast query 11
Tốt nhất cho: Team với streaming ingestion và update-heavy workload
So Sánh Tổng Hợp
| Khía cạnh | Delta Lake | Iceberg | Hudi |
|---|---|---|---|
| Mô hình metadata | Transaction log + checkpoint | Manifest hierarchy | Timeline + metadata table |
| Xử lý file nhỏ | Log-based tracking | Manifest-based tracking | Mode-dependent (COW/MOR) |
| Compaction | Manual/scheduled OPTIMIZE | Explicit rewrite API | Automatic trong MOR mode |
| Update semantic | Copy-on-write | COW hoặc deletion vector | COW hoặc MOR mode |
| Metadata overhead | Thấp (log compaction) | Trung bình (manifest layer) | Trung bình (timeline + index) |
| Use case tốt nhất | Batch analytics + ACID | Multi-engine + flexibility | Streaming + upsert |
6. Tổng Hợp: Kiến Trúc Tham Khảo
Đây là cách thiết kế một hệ thống analytical dựa trên S3:
Layer 1: Physical Layout
s3://data-lake/
raw/ # Vùng landing chưa tối ưu
events/
year=2024/month=01/day=15/
00000.json.gz
00001.json.gz
processed/ # Tối ưu cho analytics
events/
year=2024/month=01/day=15/
bucket_00/
part-00000.parquet # 256MB, 128MB row group
part-00001.parquet
bucket_01/
part-00000.parquet
_table_metadata/ # Table format metadata
delta_log/ or metadata/ # Delta hoặc Iceberg
Layer 2: Write Path
- Ingest: Đưa file nhỏ vào
raw/(chấp nhận tần suất cao) - Buffer: Batch các micro-batch nếu có thể (giảm số lượng file)
- Transform: Chuyển đổi sang Parquet với row group được điều chỉnh
- Write: Append vào table với metadata transaction
- Compact: Trigger minor compaction nếu số lượng file vượt ngưỡng
Layer 3: Compaction Job
# Pseudocode cho compaction policy
def should_compact(partition):
files = get_files(partition)
# Trigger minor compaction
if len(files) > 1000:
return "minor"
# Trigger major compaction
if partition.age > 7 days and not partition.optimized:
return "major"
return None
def compact(partition, mode):
if mode == "minor":
# Merge file nhỏ thành file 128MB
merge_small_files(partition, target_size="128MB")
elif mode == "major":
# Ghi lại toàn bộ với Z-ordering
rewrite_partition(partition,
target_size="256MB",
sort_by=["user_id", "timestamp"],
z_order=True)
Layer 4: Read Path
- Plan: Đọc table metadata (không phải S3 LIST)
- Prune: Sử dụng partition filter và file statistic
- Scan: Chỉ đọc các file và row group cần thiết
- Filter: Áp dụng predicate ở row group level
- Project: Chỉ deserialize các cột cần thiết
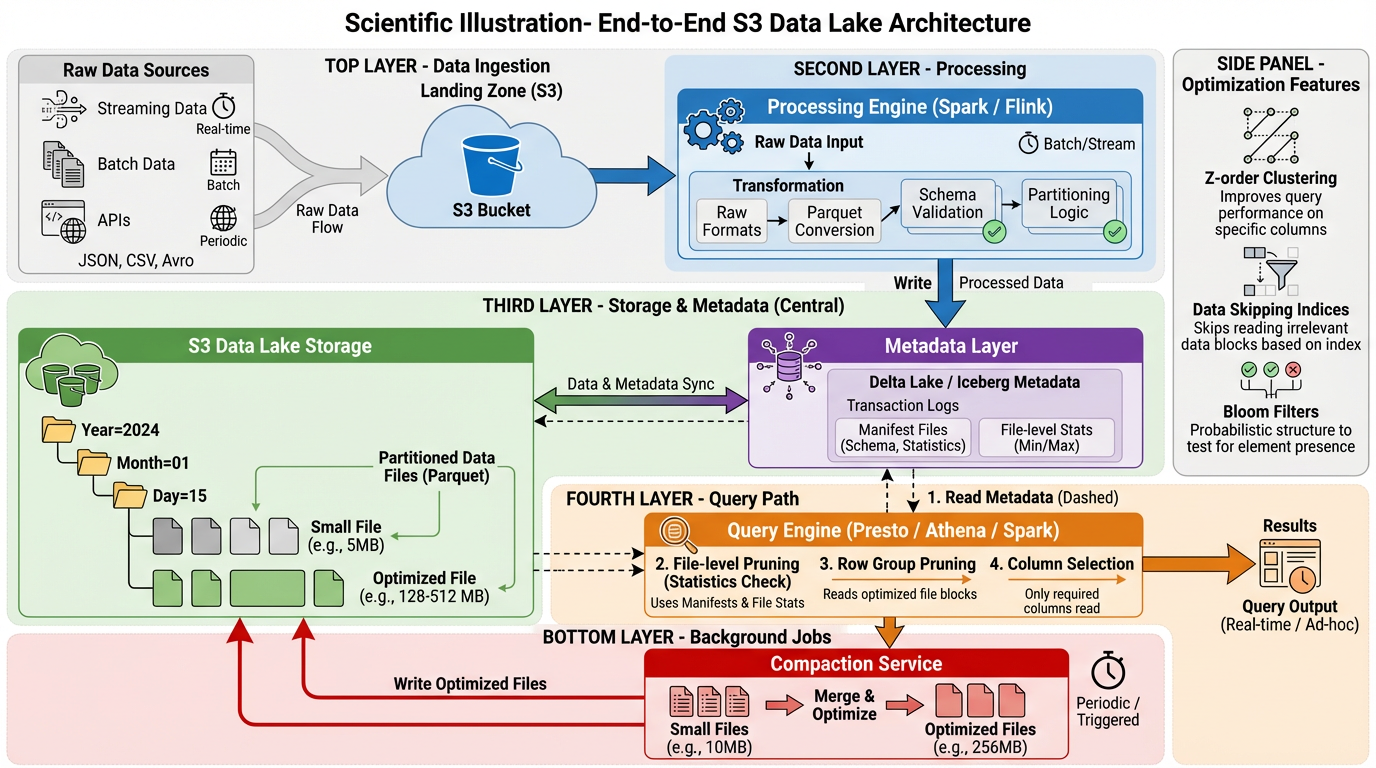
Monitoring và Tuning
Theo dõi các metric này:
- File per partition: Mục tiêu < 1000
- Average file size: Mục tiêu 128MB-1GB
- File per query: Mục tiêu < 100
- Metadata operation latency: Mục tiêu < 1s
- Read amplification ratio: Mục tiêu < 2x
- Compaction lag: Thời gian kể từ lần compaction cuối
7. Các Lỗi Thường Gặp và Cách Tránh
Lỗi 1: Listing S3 Trên Mọi Query
Triệu chứng: Query planning mất vài phút cho các bảng lớn
Giải pháp: Sử dụng table format (Delta, Iceberg, Hudi) duy trì metadata riêng biệt
Lỗi 2: Bỏ Qua File Nhỏ
Triệu chứng: Query chậm dần theo thời gian khi số lượng file tăng
Giải pháp: Triển khai automated compaction với trigger và SLA rõ ràng
Lỗi 3: File Quá Lớn
Triệu chứng: Read amplification cao, tính song song kém
Giải pháp: Điều chỉnh kích thước row group và hướng tới file 128MB-1GB, không phải monolith 10GB+
Lỗi 4: Phân Vùng Sai
Triệu chứng: Query quét toàn bộ dataset mặc dù có filter
Giải pháp: Căn chỉnh phân vùng với query pattern; sử dụng bucketing cho high-cardinality dimension
Lỗi 5: Không Có Statistic
Triệu chứng: Mọi file được mở bất kể filter
Giải pháp: Đảm bảo Parquet/ORC footer statistic được ghi và sử dụng; thêm bloom filter cho equality predicate
Lỗi 6: Compaction Starvation
Triệu chứng: Compaction không bao giờ chạy hoặc chạy quá hiếm
Giải pháp: Lên lịch compaction như một operational concern hạng nhất với tài nguyên chuyên dụng
8. Performance Benchmark và Kỳ Vọng
Dựa trên LST-Bench và các triển khai thực tế 3:
Metadata operation:
- Cold start (không cache): 1-10s cho 1M file
- Warm cache: 100ms-1s
- Với table format: 100ms-500ms (độc lập với số lượng file)
Query performance:
- Tối ưu tốt: 10-100 file được quét mỗi query
- Tối ưu kém: 10,000+ file được quét mỗi query
- Chênh lệch: 10-100x về query latency
Compaction overhead:
- Minor: 2-5x write amplification
- Major: 5-10x write amplification
- Lợi ích: Giảm 5-50x read amplification
Tác động kích thước file:
- File 1MB: Chậm hơn 10x so với tối ưu
- File 128MB: Tối ưu cho hầu hết workload
- File 10GB: Chậm hơn 2-5x so với tối ưu
Kết Luận
S3 không phải là database, nhưng với kiến trúc có chủ đích, nó có thể phục vụ như một database. Các nguyên tắc chính:
- Tránh listing: Sử dụng table format để duy trì metadata riêng biệt
- Kích thước file phù hợp: Mục tiêu 128MB-1GB với row group được điều chỉnh
- Compact liên tục: Minor compaction thường xuyên, major compaction định kỳ
- Giảm thiểu read amplification: Statistic, pruning và tối ưu hóa columnar
- Đo lường mọi thứ: Instrument metadata operation, số lượng file và read amplification
Các table format hiện đại (Delta Lake, Iceberg, Hudi) mã hóa các pattern này, nhưng hiểu các nguyên tắc cơ bản cho phép bạn điều chỉnh chúng hiệu quả—hoặc xây dựng hệ thống chuyên biệt của riêng bạn.
Cuộc cách mạng lakehouse đã cho thấy rằng object storage có thể sánh với các database truyền thống cho analytical workload. Nhưng nó đòi hỏi tôn trọng các ràng buộc của phương tiện và thiết kế phù hợp. Coi S3 như một database, nhưng thiết kế kiến trúc nó như một log-structured merge tree.
Tài Liệu Tham Khảo
Hình Ảnh Minh Họa
Bài viết này bao gồm 6 hình ảnh kỹ thuật:
- Hình 1: So sánh các scheme phân vùng (Hive-style, Date-based, Hash-based)
- Hình 2: So sánh kiến trúc metadata (Delta Lake vs Iceberg)
- Hình 3: Vấn đề kích thước file và vùng tối ưu
- Hình 4: Quá trình compaction theo kiểu LSM-Tree
- Hình 5: Tối ưu hóa Read Amplification với pruning nhiều tầng
- Hình 6: Kiến trúc S3 hoàn chỉnh từ đầu đến cuối
Viết cho các kỹ sư thực hành xây dựng data platform trên cloud object storage. Để thảo luận thêm, hãy liên hệ qua Twitter/LinkedIn hoặc mở issue trên GitHub.
Footnotes
Armbrust, M., Das, T., Sun, L., et al. (2020). Delta lake: high-performance ACID table storage over cloud object stores. Proceedings of the VLDB Endowment, 13(12). DOI: 10.14778/3415478.3415560 ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 ↩9 ↩10 ↩11
Towards Optimizing Storage Costs on the Cloud (2023). arXiv:2305.14818 ↩
Camacho-Rodríguez, J., Agrawal, A., Gruenheid, A., et al. (2023). LST-Bench: Benchmarking Log-Structured Tables in the Cloud. arXiv:2305.01120 ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7
Bringhurst, R., & Vuppalapati, R. (2024). Apache Iceberg: The Definitive Guide. O'Reilly Media. ↩ ↩2 ↩3 ↩4 ↩5 ↩6
Okolnychyi, A., Sun, C., Tanimura, K., et al. (2024). Petabyte-Scale Row-Level Operations in Data Lakehouses. Proceedings of the VLDB Endowment, 17(11). DOI: 10.14778/3685800.3685834 ↩ ↩2 ↩3 ↩4 ↩5 ↩6
Bian, H., & Ailamaki, A. (2022). Pixels: An Efficient Column Store for Cloud Data Lakes. Proceedings of ICDE 2022. DOI: 10.1109/icde53745.2022.00276 ↩ ↩2 ↩3
FlatStor: An Efficient Embedded-Index Based Columnar Data Layout for Multimodal Data Workloads. Proceedings of the VLDB Endowment, 2024. ↩ ↩2
Kalmuk, D., Garcia-Arellano, C., Barber, R., et al. (2024). Native Cloud Object Storage in Db2 Warehouse: Implementing a Fast and Cost-Efficient Cloud Storage Architecture. Proceedings of ACM SIGMOD 2024. DOI: 10.1145/3626246.3653393 ↩
Durner, D., Leis, V., & Neumann, T. (2023). Exploiting Cloud Object Storage for High-Performance Analytics. Proceedings of the VLDB Endowment, 16(11). DOI: 10.14778/3611479.3611486 ↩
High Performance Read Operations in Merge-On-Read with Deletion Vectors in Apache Iceberg (2025). SAR Council Technical Report. ↩ ↩2
Jain, P., Kraft, P., Power, C., et al. (2024). Analyzing and Comparing Lakehouse Storage Systems. Technical Report. ↩ ↩2

